출처 : 초보를 위한 정보이론 안내서 - Entropy란 무엇일까 (hyunw.kim)
초보를 위한 정보이론 안내서 - Entropy란 무엇일까
딥러닝을 공부하다 보면 KL-divergence, cross-entropy 등에서 entropy라는 용어를 자주 접하게 됩니다. 이번 글을 통해서 정보이론의 아버지라 불리는 Shannon이 주창한 기초 개념인 entropy를 정리해봅니다.
hyunw.kim
Quantity of information : 정보량
- 어떤 내용을 표현하기 위해 물어야 하는 최소한의 질문 개수
(정보는 sequential 하다고 가정함...?? 예를 들어서 정수..)

Information Entropy
- 불확실성의 정도를 나타내는 개념
- Entorpy 의 값이 크다는 것은 정보를 확정하는데 필요한 최소한의 질문 (bit) 의 개수의 평균이 높다는 뜻
- 모든 경우의 수가 동일 확률로 일어 날수록 (확률분포의 분산이 클 수록) Entropy 는 증가 함
- H 라고 표시, 단위는 bit
- 추가 설명.. :
정보 i 의 경우,
i 인지 확인하기 위해서 물어야 하는 질문의 개수는 log2 p(i) 이고,
주어진 경우의 수가 i 일 확률이 p(i) 이므로,
모든 정보를 확정 할 때, 필요한 질문 개수의 평균을 취하면 i * log2 p(i) 가 됨.



Cross Entropy
- 확률분포가 p 인 데이터에 대해, 확률분포 q 로 예상하고 질문을 할 때의, 질문 개수의 기대값
- q 가 p 에 가까워 질수록 값은 작아짐

- 머신러신에서의 활용 : p 를 학습하고 있는 상황이라면, q가 p 로 갈수록 cross entropy 는 감소함
( p는 확률 분포의 참 값, q는 우리가 학습 중인 확률분포..)
- Cross entorpy 를 최소화 하는 것은 log likelihood 를 최대화 하는 것과 같음
KL-divergence (Kullback-Leibler divergence)
- 두 확률 분포의 차이를 계산하는데 활용 됨
- 확률분포 p,q 의 cross entorpy 에서 p 의 엔트포리를 뺀 값
- Cross entropy 를 minimize 하는 것은, KL-divergence 를 minimize 하는 것과 같음
- KL divergence 를 minimize 하는 것은 log likelihood 를 maximize 하는 것과 같음
- KL divergence 의 특징으로
1. "0" 이상 2. KL-divergence 는 거리 개념이 아니며, asymmetric 하다. (p,q를 바꾼 값이 다르다)
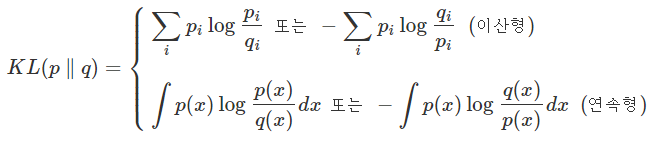
'ML, DL > 수학' 카테고리의 다른 글
| [통계 분석] 통계 기초 - 수학 기호 & 통계 기호 (0) | 2022.09.02 |
|---|---|
| 확률(probability), 가능도(likelihood), 최대우도측정(likelihood maximization) (1) | 2022.08.27 |